
Linux 内核网络中的 sk_buff 数据结构
本文转载自 houmin.cc,原文已被删除,但因为之前阅读此文感觉说明较为清楚(后来查了下主要参考的是 Understanding Linux Network Internals 这本书),因此为方便今后查看,从 wayback machine 找到并转载了这篇文章。文章内容可能有补充修正。
在 Linux 内核的网络代码中,sk_buff 或许是最重要的数据结构,用来表示已接收或将要传输的数据。 sk_buff 定义在 include/linux/skbuff.h 中,它由许多变量组成,目标就是满足所有网络协议的需要。随着数据包在内核协议栈不同层次传递时,Linux 内核不是通过层与层之间的数据拷贝,而是通过追加头信息的方式,这即是 sk_buff 被使用的典型场景:在不同网络协议层之间移动,通过添加数据头的形式传递数据。本文分析采用的是 2.6.35 版本内核。
随着内核的迭代,sk_buff 的结构已经被添加了许多新的选项,已经存在的字段也被重新整理了很多遍。可将内部的字段分为以下几类:
- Layout 负责内存布局的字段
- General 通用的字段
- Feature-specific 对应特别功能字段
- Management functions 一些用来管理 sk_buff 的函数
sk_buff 在不同的网络层次被使用(MAC 或其他在 L2 的协议,在 L3 的 IP 协议,在 L4 的 TCP 或 UDP 等),当它从一层传递到另一层时,各个字段也会发生变化。在被传递到 L3 之前,L4 会追加头信息,然后在被传递到 L2 之前,L3 会追加头信息。从一层传递到另一层时,通过追加头信息的方式比将数据在层之间拷贝会更有效率。由于要在 buff 的开头增加空间(与平时常见的在尾部追加空间相比)是一项复杂的操作,内核便提供了 skb_reserve 函数执行这个操作。因此,随着 buffer 从上层到下层的传递,每层协议做的第一件事就是调用 skb_reserve 去为它们的协议头在 buffer 的头部分配空间。在后面,我们将通过一个例子去了解内核如何在当 buffer 在各个层间传递时,确保为每一层保留了足够的空间让它们添加它们自己的协议头。
在接收数据时,buffer 会被从下层到上层传递,在从下到上的过程中,前一层的协议头对于当前层来说已经没有用了。比如:L2 的协议头只会被处理 L2 协议的设备驱动程序使用,L3 并不关心 L2 的头。那么内核怎么做的呢? 内核的实现是: sk_buff 中有一个指针会指向当前位于的层次的协议的协议头的内存开始地址,于是从 L2 到 L3 时,只需将指向 L2 头部的指针移动到 L3 的头部即可(又是一步追求效率的操作)。
Layout Fields
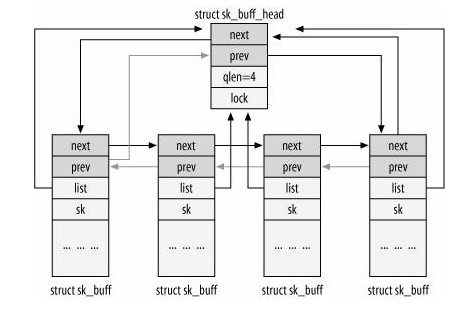
Linux 内核把系统中所有的 sk_buff 实例维护在一个双向链表中。和任何双向链表类似,sk_buff 链表的每个节点也通过 next 和 prev 分别指向后继和前驱节点。但是 sk_buff 链表还要求:每个节点必须能够很快的找到整个链表的头节点。为了实现这个要求,一个额外的数据结构 sk_buff_head 被添加到链表的头部,作为一个空节点:1
2
3
4
5
6
7
8struct sk_buff_head {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
__u32 qlen; // 表示链表中的节点数,当前的sk_buff链上包含多少个skb
spinlock_t lock; // 加锁,防止对表的并发访问
};
sk_buff 和 sk_buff_head 开始的两个字段是相同的,都是 next 和 prev 指针。即使 sk_buff_head 比 sk_buff 更轻量化,也允许这两种结构在链表中共存。另外,可以使用相同函数来操作 sk_buff 和 sk_buff_head。
为了实现通过每个节点都能快速找到链表头,每个节点都会包含一个指向链表中唯一的 sk_buff_head 的指针(list)。
下面是 layout 字段的详细解释:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26struct sk_buff {
/* These two members must be first. */
struct sk_buff *next;
struct sk_buff *prev;
struct sock *sk; // 表示从属于那个socket,主要是被4层用到。
/* ... */
unsigned int len, // 表示在 buffer 中数据区域的大小, 值会随着 buffer 在各层间传递而改变
data_len; // 和 len 不同的是,data_len 只记录分段中的数据大小
__u16 mac_len, // MAC 头部的长度
hdr_len; // header len
void (*destructor)(struct sk_buff *skb); // skb的析构函数,一般都是设置为sock_rfree或者sock_wfree
/* ... */
/* These elements must be at the end, see alloc_skb() for details. */
sk_buff_data_t tail;
sk_buff_data_t end;
unsigned char *head,
*data;
unsigned int truesize; // 表示整个skb的大小, 包括skb本身以及数据, 也就是 len+sizeof(struct sk_buff)
atomic_t users; // sk_buff 的引用计数
};
head 、end 、data 和 tail 这 4个指针用来表示 buffer 中数据域的边界。当每一层为了任务而准备 buffer 时,为了协议头或数据,可能会分配更多的空间。 head 和 end 指向了 buffer 被分配的内存区域的开始和结束, data 和 tail 指向真实数据的开始和结束。
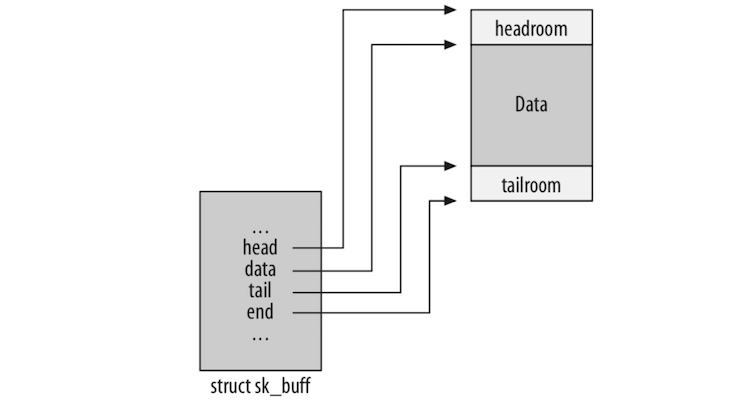
每一层能够在 head 和 data 之间的区域填充协议头,或者在 tail 和 end 之间的区域填充新的数据。
General Fields
在 sk_buff 中存在一些通用目的的字段,这些字段没有与特定的内核功能绑定:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48struct sk_buff {
/* ... */
struct skb_timeval tstamp; // 时间戳,表示何时被接收或有时表示包预定的传输时间
struct net_device *dev; // 描述一个网络设备,之后会专门分析
sk_buff_data_t transport_header; // L4 协议栈的协议头
sk_buff_data_t network_header; // L3 协议栈的协议头
sk_buff_data_t mac_header; // L2 协议栈的协议头
struct dst_entry *dst; // 由路由子系统使用,据说数据结构比较复杂
/*
* This is the control buffer. It is free to use for every
* layer. Please put your private variables there. If you
* want to keep them across layers you have to do a skb_clone()
* first. This is owned by whoever has the skb queued ATM.
*/
char cb[48]; // control buffer, 后面详细分析
// 校验相关
union {
__wsum csum;
struct {
__u16 csum_start;
__u16 csum_offset;
};
};
__u32 priority; // 优先级,主要用于QoS
// 一些标识位
kmemcheck_bitfield_begin(flags1);
__u8 local_df:1, // 是否可以本地切片的标志
cloned:1, // 设置后表示此结构是另一个sk_buff缓冲区的克隆
ip_summed:2, // 这个表示校验相关的一个标记,表示硬件驱动是否为我们已经进行了校验
nohdr:1, // 这个域如果为1,则说明这个skb的头域指针已经分配完毕,因此这个时候计算头的长度只需要head和data的差就可以了
nfctinfo:3;
__u8 pkt_type:3, // 主要是表示数据包的类型,比如多播,单播,回环等等,可在 include/linux/if_packet.h 中查看
fclone:2, // 这个域是一个clone标记,主要是在fast clone中被设置
ipvs_property:1, // ipvs 相关
peeked:1, // udp 相关,表示只是查看数据
nf_trace:1; // netfilter 相关
kmemcheck_bitfield_end(flags1);
__be16 protocol; // 从 L2 处的网卡设备驱动程序的角度来看,在更高层次上使用的协议,完整列表可在 include/linux/if_ether.h
/* ... */
};
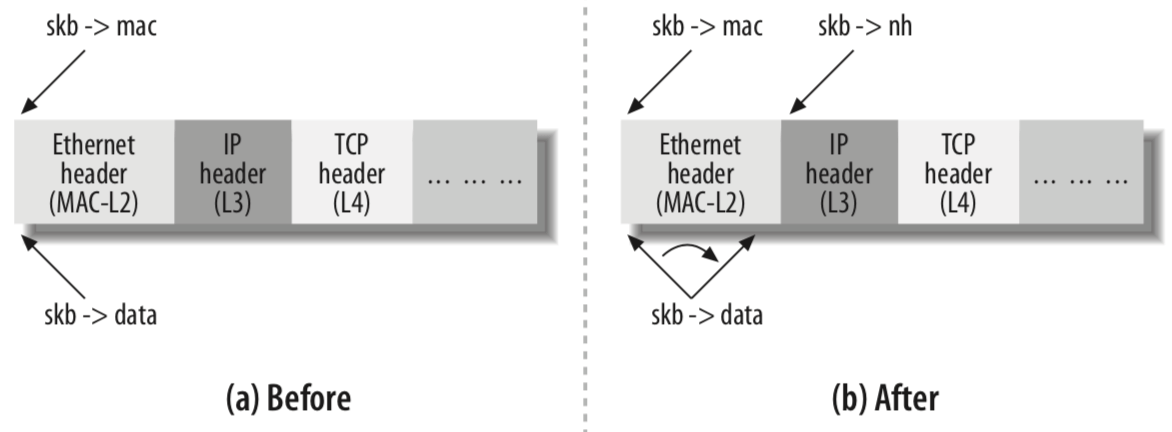
transport_header、network_header 和 mac_header 分别为 L4 、L3 和 L2 的协议头。和之前版本比较有了变化,不再是联合体,使用更加方便了,Linux给出了很方便的函数直接定位到各层的头部。下图是2.4版本的,只是说明了数据包在不同协议层移动时 data 指针的处理。
- 当接收到数据包时,负责处理第 n 层协议头的函数从第 n-1 层接收一个 buffer,其中
skb->data指向第 n 层协议头的开头。 - 处理第 n 层的函数会为此层初始化适当的指针(例如,L3 的处理函数会为
skb->nh赋值)以保留skb->data字段,因为当skb->data被赋值为 buffer 内的其他偏移量时,该指针的内容将在下一层的处理过程中丢失。 - 该函数完成第 n 层的处理,并在将数据包传递到第 n+1 层处理程序之前,更新
skb->data使其指向第 n 层协议头的末尾(即第 n+1 层协议头的开始位置)
下面说一下 control buffer ,它用来存储一些私有信息,由各层维护以供内部使用。它是在 sk_buff 结构中静态分配的(当前大小为40个字节),并且足够大以容纳每一层所需的任何私有数据。在每一层的代码中,访问都是通过宏进行的,以使代码更具可读性。例如,TCP使用该空间存储 tcp_skb_cb 数据结构,该数据结构在 include/net/tcp.h 中定义:1
2
3
4
5
6
7
8struct tcp_skb_cb {
//...
__u32 seq; /* Starting sequence number */
__u32 end_seq; /* SEQ + FIN + SYN + datalen */
__u8 tcp_flags; /* TCP header flags. (tcp[13]) */
__u32 ack_seq; /* Sequence number ACK'd */
//...
};
这是 TCP 代码访问结构的宏,宏仅由一个指针转换组成:1
这是一个示例,其中 TCP 模块在收到分段后填写 cb 结构:1
2
3
4
5
6
7
8
9static void tcp_v4_fill_cb(struct sk_buff *skb, const struct iphdr *iph, const struct tcphdr *th) {
TCP_SKB_CB(skb)->seq = ntohl(th->seq);
TCP_SKB_CB(skb)->end_seq = (TCP_SKB_CB(skb)->seq + th->syn + th->fin + skb->len - th->doff * 4);
TCP_SKB_CB(skb)->ack_seq = ntohl(th->ack_seq);
TCP_SKB_CB(skb)->tcp_flags = tcp_flag_byte(th);
TCP_SKB_CB(skb)->tcp_tw_isn = 0;
TCP_SKB_CB(skb)->ip_dsfield = ipv4_get_dsfield(iph);
TCP_SKB_CB(skb)->sacked = 0;
}
Feature-Specific Fields
Linux内核是模块化的,允许你选择要包括的内容和要忽略的内容。因此,只有在编译内核时开启支持像 Netfilter 或 QoS 之类的特定功能的情况下,某些字段才会包含在 sk_buff 数据结构中:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19struct sk_buff {
/* ... */
struct nf_conntrack *nfct;
struct sk_buff *nfct_reasm;
struct nf_bridge_info *nf_bridge;
__u16 tc_index; /* traffic control index */
__u16 tc_verd; /* traffic control verdict */
/* ... */
};
Management Functions
内核提供了许多很简短的简单函数来操纵 sk_buff 节点或链表。如果查看文件 include/linux/skbuff.h 和 net/core/skbuff.c,你会发现几乎所有功能都有两个版本,名称分别为 do_something 和 __do_something。通常,第一个是包装函数,它在对第二个调用的周围添加了额外的健全性检查或锁定机制。内部 __do_something 函数通常不直接调用。该规则的例外通常是编码不良的函数,这些函数最终将被修复。
内存分配
alloc_skb
alloc_skb 是分配缓冲区的主要函数,在 net/core/skbuff.c 中定义。
__alloc_skb 分配缓冲区和一个 sk_buff 结构,这个函数起始可以看作三部分:
- 第一部分是分配内存,由于数据缓冲区和
sk_buff自身是两个不同的结构,所以创建单个缓冲区涉及两个内存分配- 调用函数
kmem_cache_alloc从缓存中获取sk_buff数据结构 - 调用
kmalloc获取数据缓冲区,而kmalloc也会使用缓存的内存(如果可用)
- 调用函数
- 第二部分是初始化分配的 skb 的相关域
- 第三部分是处理
fclone
1 | struct sk_buff *__alloc_skb(unsigned int size, gfp_t gfp_mask, int fclone, int node) |
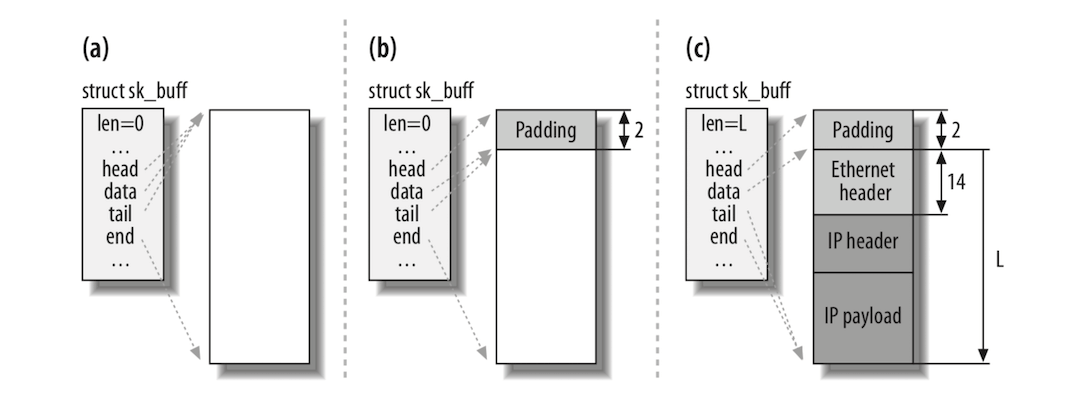
在调用 kmalloc 之前,使用宏 SKB_DATA_ALIGN 调整了大小参数以强制对齐。返回之前,该函数将初始化结构体中的一些参数,从而产生下图所示的最终结果:
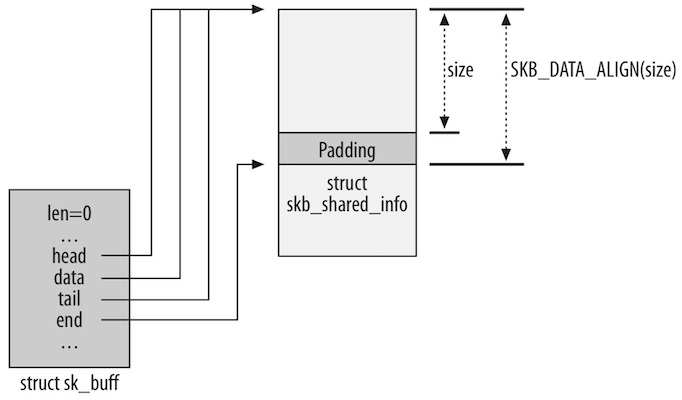
在图右侧存储块的底部,可以看到为了强制对齐而引入的 Padding 区域。 skb_shared_info 块主要用于处理 IP 的分片(IP 协议根据 MTU 和 MSS 对数据包进行的分片传输)。
__alloc_skb 函数可以叫做 Fast SKB cloning 函数,这个函数存在的主要原因是,以前我们每次 skb_clone 一个 skb 的时候,都是要调用 kmem_cache_alloc 从 cache 中 alloc 一块新的内存。而现在当我们拥有了 fast clone 之后,通过调用 alloc_skb_fclone 函数来分配一块大于 sizeof(struct sk_buff) 的内存,也就是在这次请求的 skb 的下方多申请了一些内存,然后返回的时候设置返回的 skb 的 fclone 标记为 SKB_FCLONE_ORIG,而多申请的那块内存的 sk_buff 的 fclone 为 SKB_FCLONE_UNAVAILABLE,这样当我们调用 skb_clone 克隆这个 skb 的时候看到 fclone 的标记就可以直接将 skb 的指针+1,而不需要从 cache 中取了。这样的话节省了一次内存存取,提高了 clone 的效率,不过调用 flcone 一般都是我们确定接下来这个 skb 会被 clone 很多次。
更详细的 fclone 的介绍可以看这里。
dev_alloc_skb
dev_alloc_skb() 也是一个缓冲区分配函数,它主要被设备驱动接收数据包时使用,通常用在中断上下文中。这是一个 alloc_skb() 的包装函数,它会在请求分配的大小上增加 NET_SKB_PAD 字节的空间以优化缓冲区的读写效率,它的分配要求使用 gfp_mask,为调用函数指定。1
2
3
4
5
6
7
8// allocate an skbuff for receiving
static inline struct sk_buff *__dev_alloc_skb(unsigned int length, gfp_t gfp_mask)
{
struct sk_buff *skb = alloc_skb(length + NET_SKB_PAD, gfp_mask);
if (likely(skb))
skb_reserve(skb, NET_SKB_PAD);
return skb;
}
内存释放
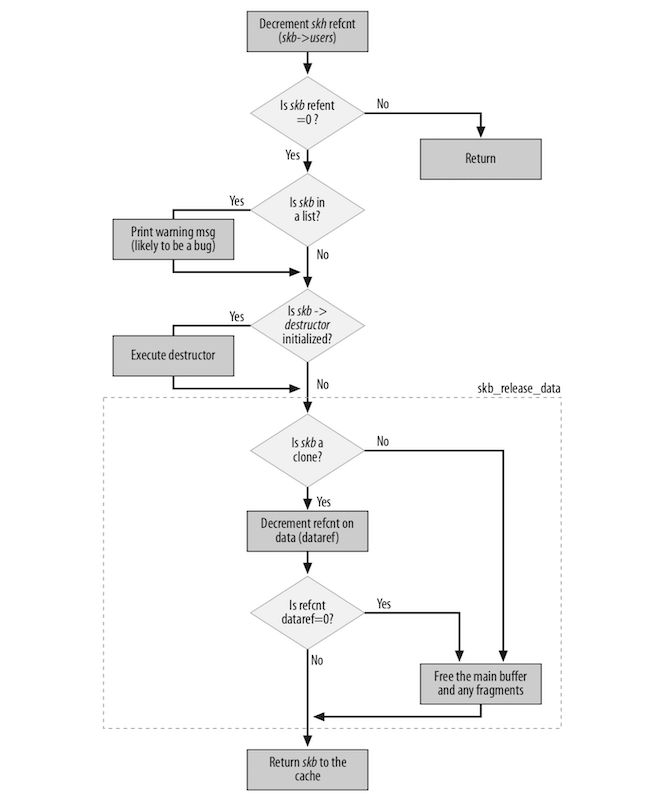
kfree_skb
kfree_skb 只有 skb->users 计数器为1时才释放,这里主要是判断一个引用标记位 users,将它减一,如果大于0则直接返回,否则释放 skb。1
2
3
4
5
6
7
8
9
10
11void kfree_skb(struct sk_buff *skb)
{
if (unlikely(!skb))
return;
if (likely(atomic_read(&skb->users) == 1))
smp_rmb();
else if (likely(!atomic_dec_and_test(&skb->users)))
return;
trace_kfree_skb(skb, __builtin_return_address(0));
__kfree_skb(skb);
}
kfree_skb 仅在 skb->users 计数器为1时(没有缓冲区的用户时)才释放缓冲区。 否则,该函数只会使该计数器递减。因此,如果一个缓冲区有三个用户,则只有当调用第三次 dev_kfree_skb 或 kfree_skb 时才会真正释放内存。
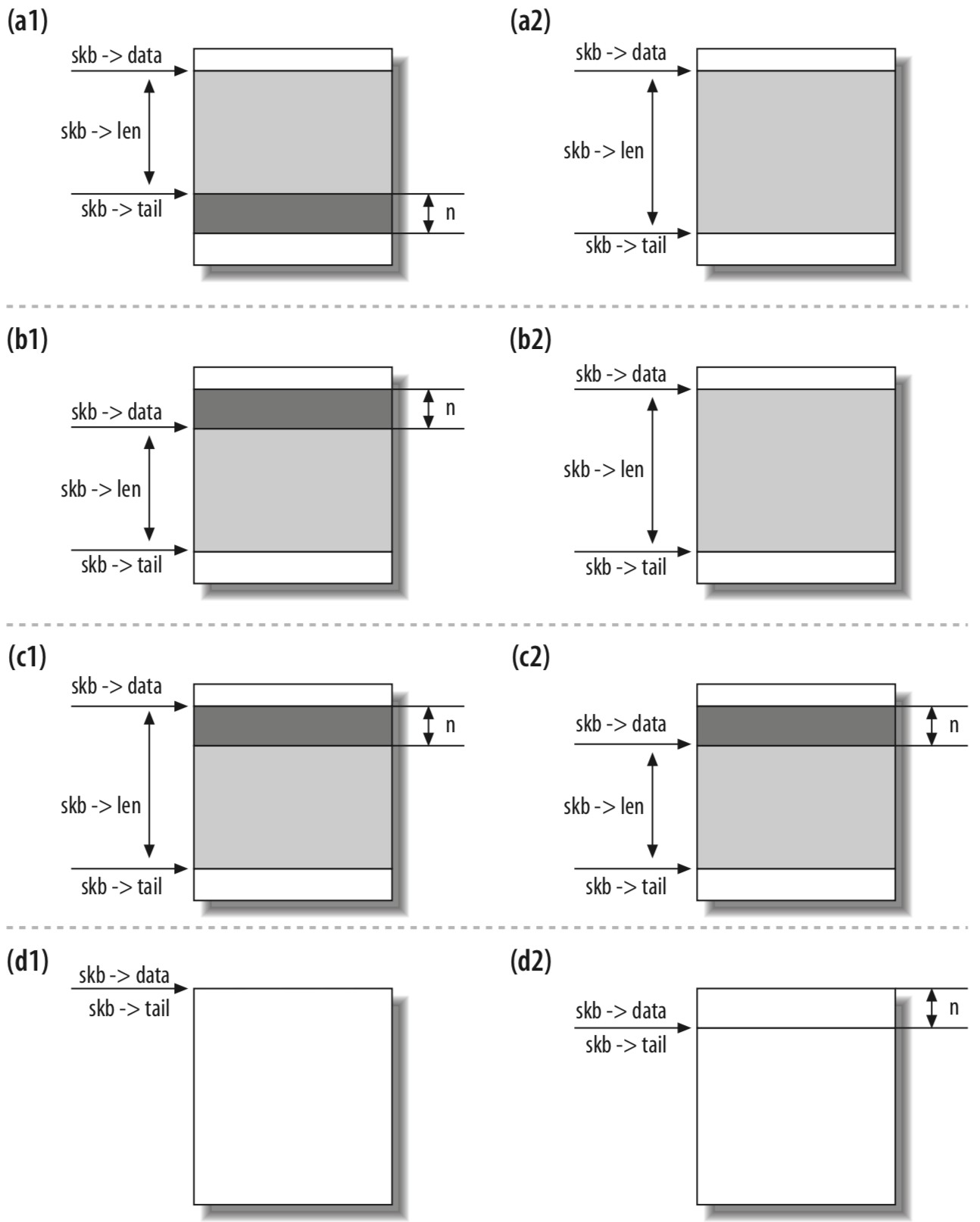
数据保留和对齐
- skb_put:在数据域尾部追加一段空间
- skb_push:在数据域的头部追加一段空间
- skb_pull:将
skb->data指针在数据域下移指定字节 - skb_reserve:在
sk_buff中skb->data之前的空间追加一段空间(在每层追加自己的协议头时常用到)
下图为分别对 sk_buff 执行 skb_put(a),skb_push(b),skb_pull©,skb_reserve(d) 的前后对比:
skb_put
先来看 __skb_put 函数,可以看到它只是将 tail 指针移动 len 个位置,然后 len 也相应的增加 len 个大小。 以下均在 /include/linux/skbuff.h 中:1
2
3
4
5
6
7
8static inline unsigned char *__skb_put(struct sk_buff *skb, unsigned int len)
{
unsigned char *tmp = skb_tail_pointer(skb);
SKB_LINEAR_ASSERT(skb);
skb->tail += len;
skb->len += len;
return tmp;
}
skb_push
__skb_push 是将 data 指针向上移动 len 个位置,对应的 len 肯定也是增加 len 大小。1
2
3
4
5
6static inline unsigned char *__skb_push(struct sk_buff *skb, unsigned int len)
{
skb->data -= len;
skb->len += len;
return skb->data;
}
skb_pull
__skb_pull 是将 data 指针向下移动 len 个位置,然后 len 减小 len 大小1
2
3
4
5
6static inline unsigned char *__skb_pull(struct sk_buff *skb, unsigned int len)
{
skb->len -= len;
BUG_ON(skb->len < skb->data_len);
return skb->data += len;
}
skb_reserve
__skb_reserve 是将整个数据区,也就是 data 以及 tail 指针一起向下移动 len 大小。skb_reserve 在缓冲区的头部保留一些空间,通常用于允许插入协议头或强制将数据在某个边界上对齐。1
2
3
4
5static inline void skb_reserve(struct sk_buff *skb, int len)
{
skb->data += len;
skb->tail += len;
}
注意,skb_reserve 函数实际上并没有将任何内容移入或移出数据缓冲区,它只是更新两个指针。
查看以太网网卡驱动程序的代码(比如: drivers/net/ethernet/3com/3c59x.c vortex_rx 函数),你能看到它们在将任何数据存储在他们刚刚分配的缓冲区中之前都会使用以下命令:1
skb_reserve(skb, 2); /* Align IP on 16 byte boundaries */
因为他们知道他们将要把协议头为 14 个字节的以太网帧复制到缓冲区中,所以参数 2 将缓冲区的 head 指针下移了 2 个字节。这将让紧跟在以太网头之后的 IP 头,从缓冲区的开头在 16 字节边界上对齐。
下图展示了 skb_reserve 在数据从上到下传递(发送数据)时的作用(为下层协议在数据区的头部分配空间):
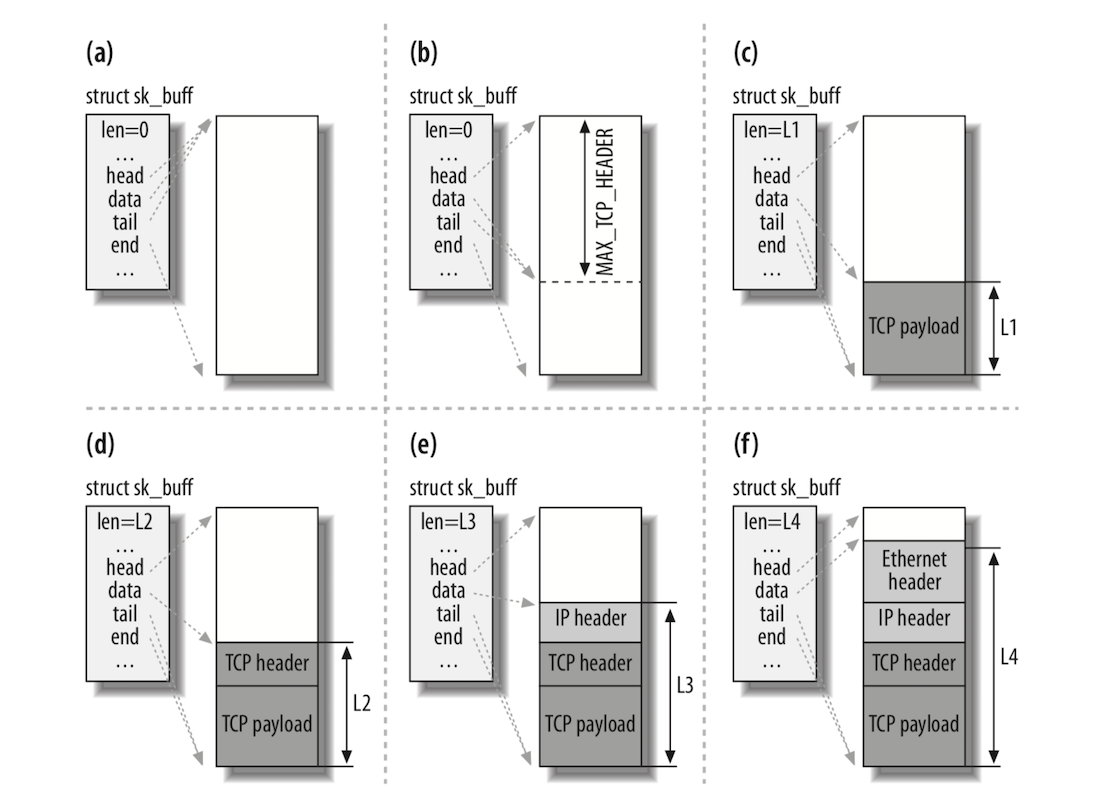
- 当要求 TCP 传输某些数据时,它会按照某些条件(TCP Max Segment Size(mss),对分散收集 I/O 支持等)分配一个缓冲区。
- TCP 在缓冲区的头部保留(通过调用
skb_reserve)足够的空间,以容纳所有层(TCP,IP,Link 层)的所有协议头。参数MAX_TCP_HEADER是所有级别的所有协议头的总和,并考虑到最坏的情况:因为 TCP 层不知道将使用哪种类型的接口进行传输,因此它为每个层保留最大的标头。它甚至考虑到多个 IP 协议头的可能性(因为当内核编译为支持 IP in IP 时,你可以拥有多个IP 协议头)。 - TCP 的 payload (应用层传输的数据)被复制到缓冲区中。请注意上图只是个例子,TCP 的 payload 可以被不同地组织,例如可以将其存储为片段。
- TCP 层添加它的协议头。
- TCP 层将缓冲区移交给 IP 层,IP层也添加协议头。
- IP 层将缓冲区移交给下一层,下一层也添加它的协议头。
请注意,当缓冲区在网络栈中向下移动时,每个协议会将
skb->data指针向下移动,在其协议头中复制,并更新skb->len。
skb_push 将一个数据块添加到缓冲区的开头,而 skb_put 将一个数据块添加到末尾。像 skb_reserve 一样,这些函数实际上并不会向缓冲区添加任何数据。他们只是将指针移到它的头或尾,数据填充应该由其他功能显式操作。skb_pull 通过将 head 指针向前移动来从缓冲区的头中删除数据块。
skb_shared_info 结构体 & skb_shinfo 函数
在上面网卡驱动拷贝帧到缓冲区的例子中出现过 skb_shared_info。它是用来保留与数据域有关的其他信息。这个数据结构紧跟在标记数据域结束的 end 指针后面。1
2
3
4
5
6
7struct skb_shared_info {
atomic_t dataref; // 代表数据域的用户数(数据域被引用的次数)
__u8 nr_frags; // 用于 ip fragmetation
struct sk_buff *frag_list; // 用于 ip fragmetation
skb_frag_t frags[MAX_SKB_FRAGS]; // 用于 ip fragmetation
//...
};
skb_is_nonlinear 函数可用于检查缓冲区是否已分段,而 skb_linearize 函数可用于将多个片段合为单个缓冲区。
sk_buff 中没有专门的指针指向 skb_shared_info 区域,skb_shinfo 函数就是方便得到指向 skb_shared_info 区域指针的函数:1
2
3
4
5
6
static inline unsigned char *skb_end_pointer(const struct sk_buff *skb)
{
return skb->end;
}
克隆和拷贝
skb_clone
当相同的缓冲区需要由不同的消费者处理,并且他们可能更改 sk_buff 结构中的内容时,为了提高效率,内核并没有克隆缓冲区的结构和数据域,而是仅复制 sk_buff 的结构,并使用引用计数进行操作,以避免过早释放共享数据块。skb_clone 函数负责拷贝一个 buffer。使用克隆的一种情况是,需要将入口数据包分发给多个接收者,例如协议处理程序和一个或多个网络分接头(Network taps)。
sk_buff 克隆不会链接到任何链表,也没有引用套接字所有者。克隆和原始缓冲区中的 skb->cloned 字段均设置为1。在克隆中将 skb->users 设置为1,以便第一次尝试删除它(被克隆的 sk_buff)时会成功,并且数据域的引用数(dataref)递增(因为现在有一个新的 sk_buff 指向了)。
skb_clone 会调用 __skb_clone:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23static struct sk_buff *__skb_clone(struct sk_buff *n, struct sk_buff *skb)
{
// 定义的宏,如果 x 是普通变量则是值赋值
// 如果 x 是指针,则是指向同一块区域
n->next = n->prev = NULL;
n->sk = NULL;
__copy_skb_header(n, skb);
//...
n->destructor = NULL;
C(tail);
C(end);
C(head);
C(head_frag);
C(data); // data 是一个指针, 所以没有克隆数据域,只是指向了数据域的内存地址
C(truesize);
refcount_set(&n->users, 1); //设置克隆的 sk_buff 的用户数为1
atomic_inc(&(skb_shinfo(skb)->dataref)); //增加数据域的引用次数
skb->cloned = 1;
return n;
}
下图为一个被分段(一个缓冲区,其中一些数据存储在与 frags 数组链接的数据片段中)了的缓冲区克隆的例子:
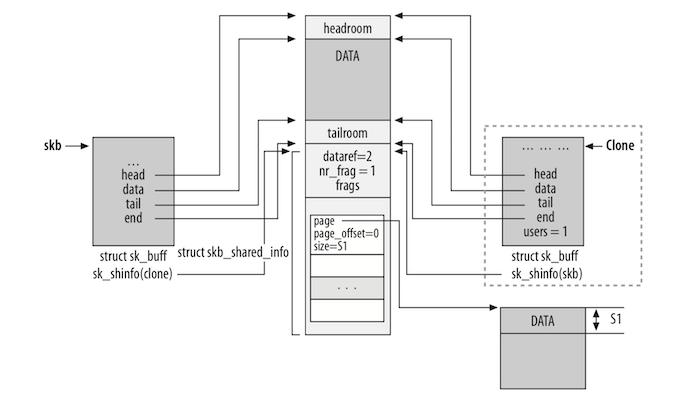
pskb_copy 与 skb_copy
当缓冲区被克隆时,无法修改数据块的内容。这意味着代码无需做同步保证即可访问数据。但是,当一个函数不仅需要修改 sk_buff 结构的内容,还需要修改数据域时,就必须要克隆数据域了。如果真要修改数据域,开发者也有两个选项可用:
- 当开发者知道自己仅仅需要修改的数据在
skb->start和skb->end的区域时,开发者可以使用pskb_copy方法只克隆那个区域。 - 当开发者认为自己或许也需要修改分段数据域时,也就是
skb_shared_info,就必须使用skb_copy。
pskb_copy 和 skb_copy 的不同如下图中的(a)和(b):
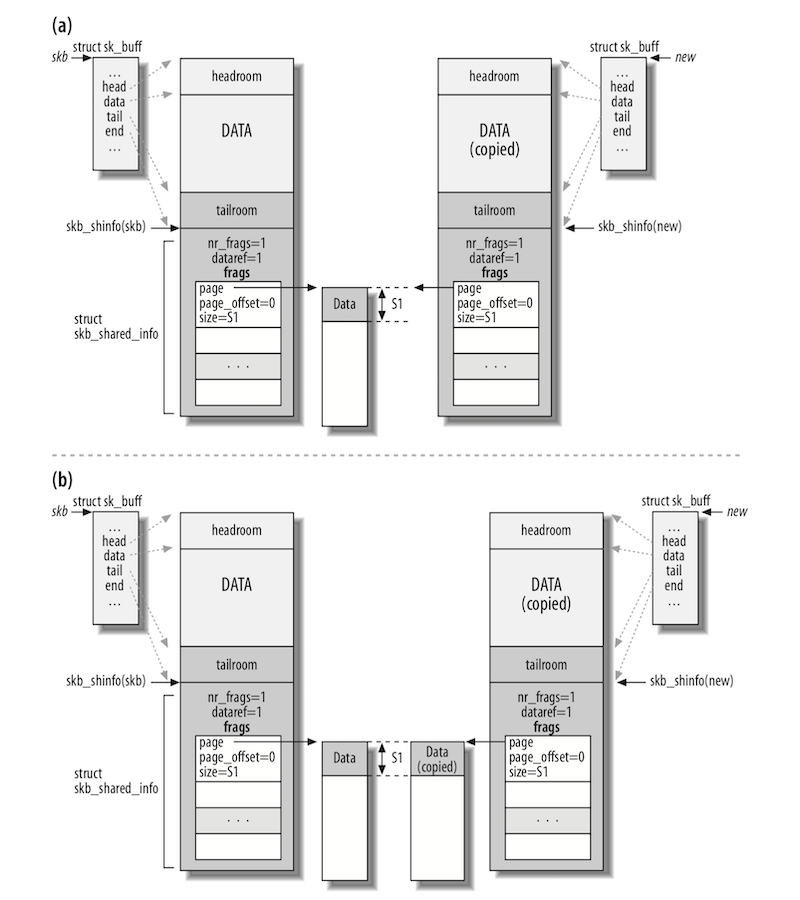
在决定克隆或复制缓冲区时,每个子系统的程序员都无法预料其他内核组件(或其子系统的其他用户)是否需要该缓冲区中的原始信息。内核是非常模块化的,并且以非常动态和不可预测的方式进行更改,因此每个子系统都不知道其他子系统可以使用缓冲区做什么。因此,每个子系统的程序员只需跟踪他们对缓冲区所做的任何修改,并注意在修改任何内容之前先进行复制,以防内核的其他部分需要原始信息。
队列管理函数
有一些函数用来维护 sk_buff 双向链表(也可以称为队列 queue)中的节点。下面是一些常用的功能函数:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51// skb_queue_head - queue a buffer at the list head
void skb_queue_head(struct sk_buff_head *list, struct sk_buff *newsk)
{
unsigned long flags;
spin_lock_irqsave(&list->lock, flags);
__skb_queue_head(list, newsk);
spin_unlock_irqrestore(&list->lock, flags);
}
// skb_queue_tail - queue a buffer at the list tail
void skb_queue_tail(struct sk_buff_head *list, struct sk_buff *newsk)
{
unsigned long flags;
spin_lock_irqsave(&list->lock, flags);
__skb_queue_tail(list, newsk);
spin_unlock_irqrestore(&list->lock, flags);
}
// skb_dequeue - remove from the head of the queue
struct sk_buff *skb_dequeue(struct sk_buff_head *list)
{
unsigned long flags;
struct sk_buff *result;
spin_lock_irqsave(&list->lock, flags);
result = __skb_dequeue(list);
spin_unlock_irqrestore(&list->lock, flags);
return result;
}
// skb_dequeue_tail - remove from the tail of the queue
struct sk_buff *skb_dequeue_tail(struct sk_buff_head *list)
{
unsigned long flags;
struct sk_buff *result;
spin_lock_irqsave(&list->lock, flags);
result = __skb_dequeue_tail(list);
spin_unlock_irqrestore(&list->lock, flags);
return result;
}
// skb_queue_purge - empty a list
void skb_queue_purge(struct sk_buff_head *list)
{
struct sk_buff *skb;
while ((skb = skb_dequeue(list)) != NULL)
kfree_skb(skb);
}
操作队列的所有函数都必须保证是原子操作。也就是说,它们必须获取 sk_buff_head 结构提供的队列自旋锁。否则,它们可能会被异步事件中断,这些异步事件会使队列中的元素入队或出队,例如到期计时器调用的函数会导致争用条件。
参考资料
- Linux Foundation Wiki: sk_buff
- Understanding Linux Network Internals: Section 2.1. The Socket Buffer: sk_buff Structure
Linux 内核网络中的 sk_buff 数据结构



