
nvdimm 技术与编程模型概览
nvdimm,即非易失性双列直插式内存模块(non-volatile DIMM),相对于传统的易失性内存,nvdimm 在断电后其中的内容也不会消失。
定义于 ACPI(NFIT),UEFI(BTT),带外通信使用 DSM。
交错本来是传统易失性内存中的一个概念。N 代表数字,和 N 通道不是一个概念,只有交错后才能叫做 N 路.
理论
本节参考 Programming Models for Emerging Non-Volatile Memory Technologies 和 Persistent Memory Programming 这两篇文章,讲述几种理论上的持久化内存编程模型和有关的问题。文章中的 NVM 泛指各种非易失性内存设备。
编程模型
理论上有很多种可能的持久化内存编程模型,这里主要聚焦在最相关的的四种。NVM Block Mode 和 NVM File Mode 代表的是过去最常用的储存接口,PM Volume Mode 和 PM File Mode 则主要针对持久内存。
NVM Block Mode
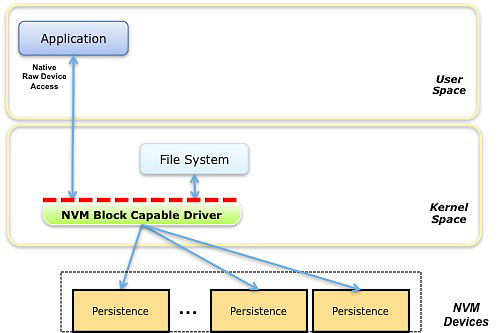
上图表示了常见软件栈的一部分,红线表示了 NVM Block Mode 的接口,这里的接口指的是块读写接口。可以看到,在这个模型中驱动向文件系统等内核模块或直接向应用程序(如直接打开 /dev/sda1 设备)提供了传统块读写接口。为了使这种传统的接口更好的支持非易失性内存设备,可能需要对它进行功能上的扩展,以得到 I/O 性能的优化,例如一些原子操作的支持,向应用程序提供非易失性内存的某些属性等。通过将这种扩展标准化,能够为软件编写者提供一个更有效的生态系统来开发非易失性内存感知的应用程序。
NVM File Mode
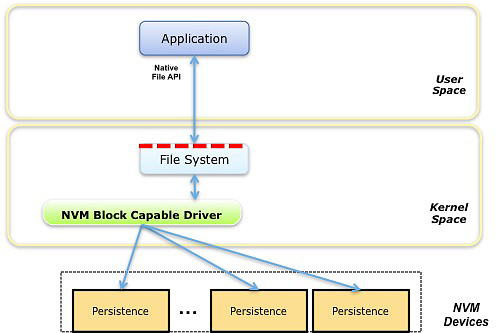
NVM File Mode 模式中主要关注的是应用程序和文件系统间的文件接口。和 NVM Block Mode 一样,为了更好的支持非易失性内存设备,文件接口可能需要进行一些扩展。
例如,MySQL 数据库的双重写入技术防止数据库在遇到电源故障等情况时,储存在文件中的数据表中的页面只被部分写入。如果数据库能够感知到硬件能够保证对于一定大小的页面写入不会因为系统中断导致撕裂,就可以避免双重写入的过程。为应用程序提供一个获取 powerfail write atomicity 的接口可以让程序自己决定合适的行为。
PM Volume Mode
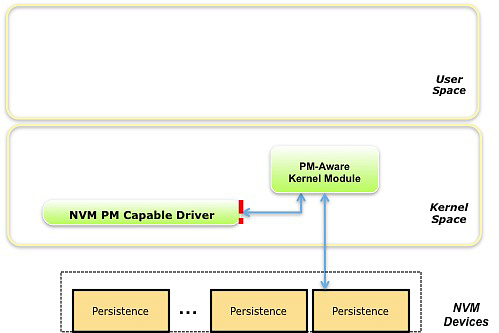
如上图,在 PM Volume Mode 中,非易失性内存设备(NVM devices)是支持 PM 的,意味着设备可以通过处理器的 load 和 store 指令直接操作。尽管任何储存元件都可能通过一种处理器可以直接从中加载数据的方式连接到系统,但 NAND Flash 等技术会使处理器在加载时暂停,使得这种连接方式难以实现。更先进的非易失性内存设备和缓存技术使得这种方式成为可能。
在 PM Volume 模式下,内核组件可以直接访问持久内存区域。上图中红线标出的接口使得能够感知 PM 的内核模块和 NVM 驱动进行通信,这是为了让内核模块获取持久内存的物理地址范围。在这之后他就不再需要调用 NVM 驱动,而是直接通过地址访问持久内存。
PM File Mode
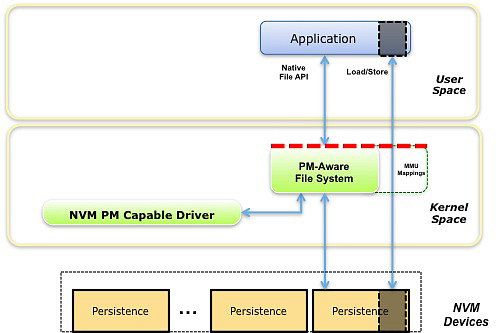
PM File Mode 看起来和 NVM File Mode 有些相似,但不同的是这里的文件系统是感知 PM 的,可以看到这种文件系统就是通过上文的 PM Volume Mode 模型实现的。
感知 PM 的文件系统提供了所有传统文件系统会提供的文件接口,实际上它通常通过在已有的文件系统的基础上扩展 PM 感知能力来实现的。这种模式最主要的特点是,在使用 mmap 将一个文件 map 到内存空间时,应用程序可以绕过内核直接 load/store 持久内存,而在传统文件系统中文件 mmap 到内存中时需要使用 page cache 机制。
Persistent Memory
与 NVM Block Mode 和 NVM File Mode 的增量式改进不同,PM 的改进更具有颠覆性。正如 CPU 从提高频率到提高核心数量的转变时应用需要重新思考他们的算法并转向多线程编程一样,PM 结合了持久性和无需先进行块 I/O 的能力,它使我们重新思考数据结构以什么形式持久的储存。
申请 PM 内存
比较自然的想法是参考 malloc 设计一个对应的持久内存版本:1
ptr = pm_malloc(len); /* the naïve solution */
看起来很合理,但很快我们就能发现其中的问题:应用之所以申请一段持久内存是为了持久的储存一些数据,因此应用需要一种方式来在重启后重新找到那片内存,因此应用需要给这片内存一个名字用于在下次重新找到它。有很多现成的命名方式供我们使用,例如对象 ID 或者类似 URL 的字符串。在命名后的下一个问题是如何确定应用有这片内存的访问权限,随着对 PM 管理方式的探究,还能发现更多问题,例如系统管理员如何修改 PM 权限、如何删除或重命名 PM、如何备份等等。对于传统储存,这些问题的答案是文件系统,所以尽管持久储存更像系统内存,以文件系统的形式暴露出来会是一个更方便的解决方案。文件 API 为 PM 区域提供了自然的命名空间,提供了创建、删除、重命名和调整大小的方法。当应用需要持久内存时,直接在感知 PM 的文件系统上打开或创建一个文件,并使用 mmap 将它映射到自己的地址空间即可。
持久化数据
需要储存的数据通常都会被缓存,并且需要通过某种同步 api 来将更改提交到储存介质。对于被映射到内存中的文件来说,msync 实现了该功能。传统 msync 将 page cache 中的数据刷新到储存中,而由于持久内存不需要 page cache,对应的 msync 调用的功能就变成了刷新 CPU cache 或其他保证数据被提交至电源故障安全的状态所需的中间步骤。
地址无关的数据结构
持久内存对于那些需要储存数组、树、堆等数据结构的应用来说很方便,应用可以利用文件 api 映射持久内存来直接访问这些结构。这带来了有关地址无关的数据结构的问题。
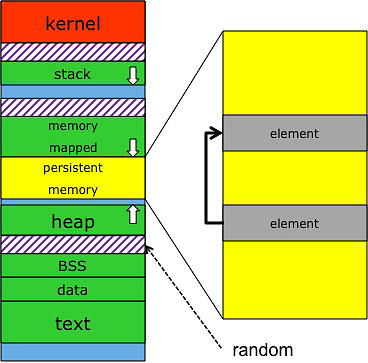
如上图,进程通过内存映射的方式访问持久内存,持久内存和其他映射到内存的文件(如共享库)一起被映射到内存空间中。各个区域之间有一些带状的空间(阴影部分区域),这片空间的具体大小通常是随机的,这是一种缓解某些类攻击的安全机制。这使得储存在持久内存上的数据结构中的指针会在第二次运行时变得无效,如上图的右侧部分所示。尽管这个问题在映射到内存的文件中就存在了,持久内存的出现使其变得更加普遍。
显而易见的解决方法是只储存相对 PM 的指针,这种方式需要每个指针解引用都清楚它是一个相对的指针并在其基础上加上一些偏移,因此比较容易出错。有运行时虚拟机或没有显式指针的语言可能可以透明的处理这种情形。一些编译器有 based pointer 这种特性,如微软的 C++ 编译器,使用特殊关键字声明的指针能够在解引用时根据基地址自动计算正确的值,使用起来更加方便。
错误处理
计算机系统的主存储器通常通过纠错码(ECC)等机制来防止错误。当该内存被应用程序使用时,应用程序通常不处理错误,可纠正的错误被纠正的过程对应用程序而言是透明的(这些错误通常被记录下来供管理员使用)。对于不可纠正的错误,操作系统在可能的情况下可以修复被破坏的应用程序内存(例如,如果内存内容没有被修改,可以重新从磁盘读取数据)。但总会有程序状态被破坏,无法安全的继续运行程序的情况。在大多数 UNIX 系统中,受影响的程序在这种情况下被杀死,UNIX 信号 SIGBUS 最常在此时被使用。
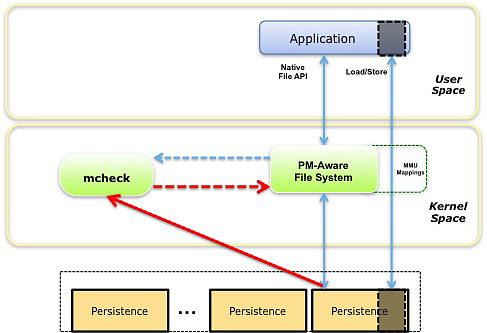
PM 的错误处理初看起来和内存相似,以在 Intel 架构上运行的 Linux 为例,内存错误是通过英特尔的 Machine Check Architecture(MCA)来报告的。当操作系统启用这一功能时,上图中的红色实心箭头显示了不可纠正错误的处理流程,当发生错误的位置被访问时,mcheck 模块会收到通知。
如之前所述,这时向应用程序发送 SIGBUS 信号可以让应用程序决定该做什么,然而由于这片区域是持久内存文件系统某个文件的一部分,即便应用程序会收到信号阻止它使用损坏的数据,也必须提供一个从这种情况中恢复的方法。系统管理员可能会尝试在更换有问题的 PM 之前备份文件系统中的其他数据,但是在我们目前所述的错误机制下,备份程序每次接触到损坏的位置都会收到一个 SIGBUS。在这种情况下,PM 感知的文件系统需要一种机制来接收错误通知,以便它能够隔离受影响的区域,继续提供对 PM 文件系统其余部分的访问。上图中的虚线箭头表示了这种机制,在启动时,文件系统告诉 mcheck 模块哪些 PM 地址范围是自己负责的,之后当错误发生时,文件系统会被 mcheck 模块调用来获得处理这个错误的机会。[1]
持久内存层的引入为应用程序开发人员提供了放置数据和数据结构的位置的新选择。传统上,数据被读取和写入易失性内存,然后刷新到非易失性持久存储。当应用程序启动时,必须先将数据从存储器中读取到易失性存储器中,然后才能对其进行访问。根据工作数据集的大小,这可能需要几秒钟、几分钟或几小时。通过巧妙的应用程序设计,开发人员和应用程序架构师现在可以利用这项新技术来提高性能并减少应用程序启动时间。持久内存引入了一些新的编程问题,这些问题不适用于传统的易失性内存。包括:数据持久性:在刷新之前,不能保证存储是持久的。尽管这对于已有数十年历史的内存映射文件 API(如 Linux 上的 mmap() 和 msync())也是如此,但许多程序员还没有处理需要刷新到内存持久性的问题。遵循标准 API(如 msync() 刷新对持久性的更改)能够按预期工作。但是更优化的刷新使得应用程序直接从 CPU 缓存中刷新存储,而不是调用内核,也是可能的。
CPU 具有无序的 CPU 执行和缓存访问/刷新。这意味着如果应用程序存储了两个值,它们持久化的顺序可能不是应用程序写入它们的顺序。数据一致性:
8 字节存储在 x86 架构上是电源故障原子性的——如果在向对齐的 8 字节存储到 PMEM 期间发生电源故障,则在重新启动后该位置或者上旧的 8 字节或者是新的 8 字节(而不是两者的结合)。
x86 上大于 8 字节的任何内容都不是 powerfail atomic 的,因此需要由软件来实现一致性所需的任何事务/日志记录/恢复。请注意,这是特定于 x86 的——其他硬件平台可能具有不同的原子性大小(PMDK 的设计目的是让使用它的应用程序不必担心这些细节)。内存泄漏:持久存储的内存泄漏是持久的。重新启动服务器不会更改设备上的内容。在当前的 volatile 模型中,如果应用程序泄漏内存,重新启动应用程序或系统会释放该内存。字节级访问:应用开发者可以根据应用需求进行字节级别的读写。读/写不再需要对齐或等于存储块边界,例如:512byte、4KiB 或 8KiB。存储不需要读取整个块来修改几个字节,然后将整个块写回持久存储。应用程序可以根据需要随意读/写。这提高了性能并减少了内存占用开销。错误处理:应用程序可能需要直接检测和处理硬件错误。由于应用程序可以直接访问持久内存介质,因此任何错误都将作为内存错误返回给应用程序。
PMEM
DAX
BTT
实现
Linux 上关于持久内存的配置概念方面曾经有过一些变动,本章节将以本文撰写时最新内核和工具的支持情况为基础。
nvdimm 技术与编程模型概览



